

Computer Science @USC
The following question was asked in the programming round of Yahoo! recruitments last year in our college.. Here's the problem statement.
A program to check whether the spelling of a given word is correct or not. If not, word suggestions must be provided. A dictionary will be provided which contains one word per line. (~ 42,000 words, 102 KB ).
The first algorithm that comes to our mind is this :
Scan through the file. Take every single word. Compare it with the accepted key. If no words match with the key, then the spelling is incorrect.
What about suggestions?!
There's a simple way for that also 😛 Compare individual characters of the key with every single word in the file. ie. If the characters match at same positions, then increment a count variable, like this:
NOBILE
Out of the 6 characters, 5 of them match which are in the same position [OBILE]. We can take a factor, something like this :
K= no_of_matched_characters / Total_no_of_characters
If this factor is greater than say 0.8 which is true for this case (5/6), we can suggest MOBILE wherever we encounter NOBILE.. This works out but fails in many cases. So, this is how i first solved the problem but i knew that i was not doing a good job with that.
What about the complexity of this method?!
We will be reading the file everytime we want to check the spelling of a word. This is not feasible and we should try to have the entire wordlist in memory. Yes, we need to use a good data structure to perform this. Using a linked list won't help in this case since we'll be comparing each and every word in the list with the key.. We need a data structure which is much more efficient. Trees can be of great use in such contexts.
The data structure TRIE {pronounced TREE, ( Re ' trie' val ) 😊 } is very good when we are handling dictionaries. The worst case complexity is considered to be O(n) where n is the length of the string to be searched for. This is how it looks..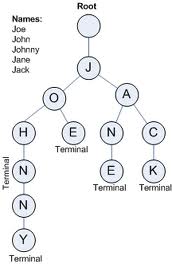
The path from the root to the terminal node is determined by the individual characters in the string. If we want to find "JOE" in the trie, we just need to traverse 3 times within the trie. This is one of the most efficient methods.
Implementation
Here, i'm using a class with 3 data members. The character info holds the character(the path to the terminal node). The string Word holds the words scanned from the file. (Note: Only in the terminal nodes) and ptrs is an array of pointers. I used a class for this purpose since the constructor was very helpful in this case.
The spell check works fine.. But there is a catch in suggestions.
What if the first character itself is wrong? 😊 we won't get the suggestion even if the rest of the string is correct? This is something even I'm trying to figure out..
Download the Wordlist (Right click & save as) as well since its needed for the program to run.
If there are any suggestions, please feel free to comment about it..
Hi Krishna,
Nice implementation. Thought of sharing my article (which includes implementation for many operations) on TRIE to get your thoughts/inputs.
Implementation:
http://yourbitsandbytes.com...
Hi Sesha,
I did go throug your implementation of Trie, and it does a lot more things. and you have explained it in a very nice way. Functions like has prefix can be very useful. Thanks for sharing.